


Le Data Engineering : Origines du métier, écosystème actuel et perspectives d’avenir
#HumanDataBrève histoire
Lorsqu’on parle du Data Engineering, on pense souvent que c’est un nouveau domaine qui a vu le jour avec l’ère du Big Data. Mais en vrai ses origines remontent à des périodes très antiques, où des civilisations telles que les Romains ou les Egyptiens ont dû développer constamment des moyens innovants pour stocker et traiter leurs informations (e.g utilisation des tablettes d’argile et des papyrus).
Cet esprit d’innovation s’est poursuivi jusqu’à l’ère moderne, où il y a eu plusieurs tournants dont le plus important est celui de l’ambitieuse mission Appollo de la Nasa en 1960 qui a nécessité la gestion des volumes de données sans précédent pour l’époque. Le besoin de collecter, stocker et interroger d’énormes quantités de données provenant des capteurs de la fusée a conduit au développement de systèmes de gestion de bases de données intégrées, précurseurs majeurs des techniques modernes de l’ingénierie des données.
La création du langage SQL dans les années 1970 a aussi marqué une étape clé dans l’évolution de l’ingénierie des données. Ce langage de programmation a rendu la gestion des données beaucoup plus simple et accessible. Sauf qu’avec l’arrivée d’internet dans les années 1990, le volume des données générées a augmenté de manière exponentielle.
Cela a créé un nombre de défis au niveau des systèmes de stockage et d’analyse des données, et a révélé pour la première fois les limites des bases de données relationnelles.
Confronté à cette problématique, les ingénieurs data ont dû adapter leurs solutions en passant vers un mode de traitement distribué au lieu du mode traditionnel et centralisé : Et c’est dans ce contexte que Hadoop a été créé en 2006.
Mais bien qu’il soit puissant avec son système de stockage distribué (HDFS), Hadoop montrait également quelques limites au niveau des calculs parallèles du fait qu’il ne supportait que le modèle MapReduce (développé par les équipes de Google en 2004). Ce dernier n’était pas très efficace pour les calculs itératifs (typiques dans les algorithmes de Machine Learning) et les traitements des données en temps réel.
Quelques années après, les équipes de Facebook ont développé Hive : un moteur d’exécution de requêtes SQL permettant d’interroger des données massives dans un cluster Hadoop. Mais malgré les facilités qu’il a pu apporter par rapport à MapReduce, Hive n’avait pas trop amélioré la rapidité des calculs.
C’est à ce moment-là que Spark a été développé pour surmonter les limites de MapReduce et Hive.
A la différence de ces derniers qui s’appuient sur la lecture et l’écriture sur disque, Spark utilise plutôt la mémoire vive (RAM) ce qui le rend beaucoup plus rapide. En 2014, il a battu le record du Daytona GraySort Contest qui était détenu par Hadoop, en traitant 100 To de données 3 fois plus rapidement et avec 10 fois moins de machines. Et depuis lors, Spark a régné sur le domaine du Data Engineering.
Le Data Engineering en 2023 : Où en somme nous ?
Presque 10 ans après l’apparition de Spark, l’écosystème actuel du Data Engineering est devenu plus riche est diversifié que jamais. De nombreux outils spécialisés ont émergé pour répondre à des besoins spécifiques, allant de l’ingestion des données à leur stockage, leur traitement et leur analyse. Ces outils sont devenus de plus en plus performants, permettant aux ingénieurs des données de manipuler des volumes de données toujours plus importants avec une efficacité accrue.
La montée du Cloud a marqué une étape très importante dans cette évolution, en permettant non seulement l’accès à un stockage des données quasi illimité et une puissance de calcul très élevée et flexible, mais aussi l’utilisation de nouveaux outils et services très innovants et spécifiquement conçus pour le Cloud. Par exemple les fonctions « serverless » qui sont devenues possibles grâce à la scalabilité que propose le Cloud.
Ecosystème du Data Engineering en 2023
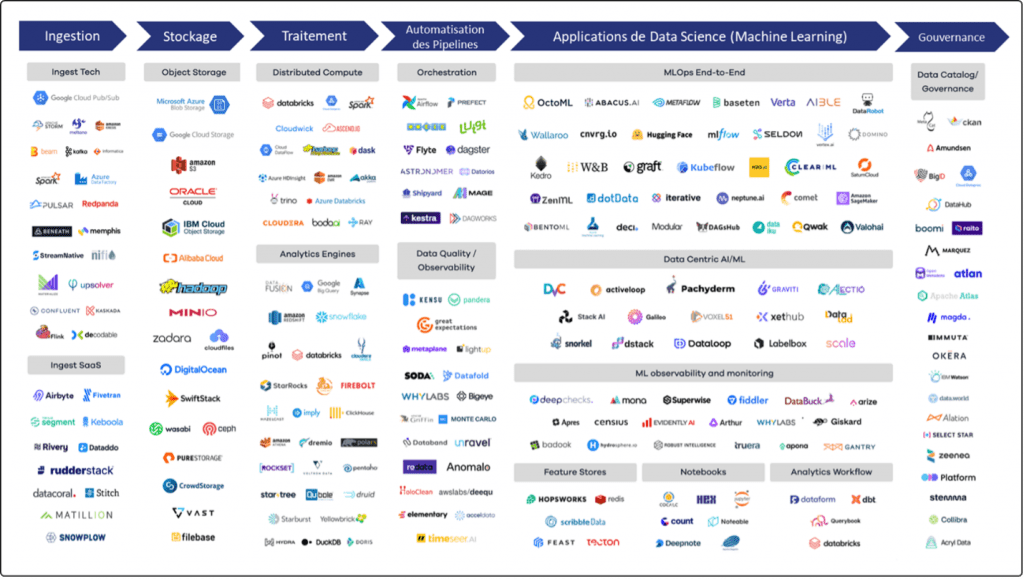
Ainsi le Cloud a considérablement enrichi l’écosystème du Data Engineering, en offrant une palette d’outils et de technologies encore plus large pour chaque étape du processus de l’ingénierie des données :
- Ingestion des données : Il s’agit de la phase où les données sont collectées à partir de diverses sources. Parmi les outils les plus populaires aujourd’hui on trouve : Kafka, Azure Data Factory, Amazon Kinesis, Spark Streaming
- Stockage : Une fois les données collectées, elles doivent être stockées de manière efficace et organisée. Hadoop HDFS a été pendant longtemps la référence pour le stockage distribué de grandes quantités de données. Cependant, le Cloud a révolutionné le stockage des données avec des solutions comme Amazon S3, Google Cloud Storage, et Azure Blob Storage
- Analytics et Computing : Ces outils permettent de traiter et d’analyser les données. Spark domine largement ce segment, grâce à son utilisation efficace de la mémoire et à son support pour divers langages de programmation (Python, R, Java, Scala). Hive et Impala offrent toujours une interface SQL pour interroger les données stockées dans Hadoop. Des plateformes d’analyse de données comme Cloudera, Databricks, Snowflake ou Google BigQuery sont également populaires
- Orchestration des pipelines : Une fois que les données sont ingérées, stockées, et prêtes à être analysées, elles doivent souvent passer par plusieurs étapes de transformation. Des outils d’orchestration comme Apache Airflow, Oozie et Google Cloud Composer permettent de planifier et de gérer ces pipelines de données complexes, en assurant que chaque étape soit exécutée dans le bon ordre et en gérant les dépendances entre elles.
- L’ingénierie du Machine Learning : L’étape du MLOps constitue les opérations d’industrialisation et de maintenance des modèles de Machine Learning qui sont déployés en production. On y trouve les outils comme Amazon SageMaker, KubeFlow, ou HuggingFace
- Data Gouvernance : Cette dernière étape contient les outils qui permettent de garantir que les données sont gérées d’une manière sécurisée et en conformité avec les réglementations internes et externes à l’entreprise. On y trouve notamment Apache Atlas, Collibra ou Alation
On constate ainsi le progrès remarquable qu’a connu l’écosystème du Data Engineering ces dernières années. Nous sommes passés d’un système dominé par deux outils, Hadoop et MapReduce, à une chaine de process foisonnant plusieurs dizaines d’outils très spécialisés pour répondre à chaque besoin, de l’ingestion des données à leur analyse, en passant par le stockage, le calcul, l’orchestration des pipelines, et bien plus encore.
Perspectives d’avenir
Compte tenu du contexte économique actuel marqué par de nombreuses incertitudes, plusieurs métiers de la data ont subi des impacts significatifs, notamment pour les Data Scientists. Cependant, les profils de Data Engineers sont toujours très demandés par les entreprises en ce moment.
Un des segments qui pourrait potentiellement connaître des évolutions majeures serait celui de l’ingénierie du Machine Learning / MLOps, notamment avec l’intégration progressive des nouvelles fonctionnalités pour les grands modèles de langage LLM-Ops.
Par ailleurs, l’impact des nouvelles technologies d’IA générative qui sont apparues cette année (ChatGPT, DallE, Midjourney, …) reste encore à déterminer. Bien que leurs implications ne soient pas encore entièrement claires par rapport au métier du data engineering, elles pourraient conduire à des changements significatifs dans la manière dont les ingénieurs abordent la gestion, le stockage et le traitement des données.


