Relevance feedback Octopeek R&D project
#HumanDataIn a previous article, Julien Hay introduced the Renewal project. This project was presented at the NeurIPS conference in December 2018. Julien is a PhD student and Data Scientist, specializing in artificial intelligence and natural language processing (NLP). The Renewal Platform has been built for the benefit of research teams. It allows them to test and compare their algorithms for the recommendation of news articles.
In the second part of our interview, Julien explains the relevance feedback that allows real-time benchmarking of competing systems.

The Renewal Project – Relevance feedback
CTR (click-through rate) is a KPI that is widely used in rating recommendation systems. It measures the performance of a system by the number of clicks it generates, normalized by the number of times its recommendations have been displayed.
CTR has some disadvantages
The CTR indicates how well a system is able to attract via its article offerings and to generate clicks. In effect, at this stage, the user sees only the title of the article. This directly benefits “clickbait”. It does not measure the actual satisfaction of a user, which can be evaluated by using reading time of articles or expressly stated satisfaction. It does not directly allow A/B testing type comparison. (See previous post.)
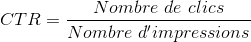
Click and Read, a true KPI of satisfaction
In the case of recommendation of news articles, the satisfaction of a user is related to their appreciation of the articles recommended to them by the system. The system should recommend articles that are sufficiently relevant to the interests of the user. It must also provide new content that will allow the reader to discover new topics of interest.
Our hypothesis is: the longer the user stays on the page and browses an article page in its entirety, the more they appreciate the article recommendation offered. The satisfaction of a user is calculated from the reading time and the scroll length of the page.
When the user has read an article long enough in accordance with a previously defined threshold, we will consider the reader satisfied. If the user has clicked and then left the article page in a short period of time, we will consider that negative feedback. This relevance feedback is in contrast to the CTR since it considers all clicks as positive feedback.
This new KPI is called “Click-And-Read”. We introduce it into opposition in the form of A/B testing.
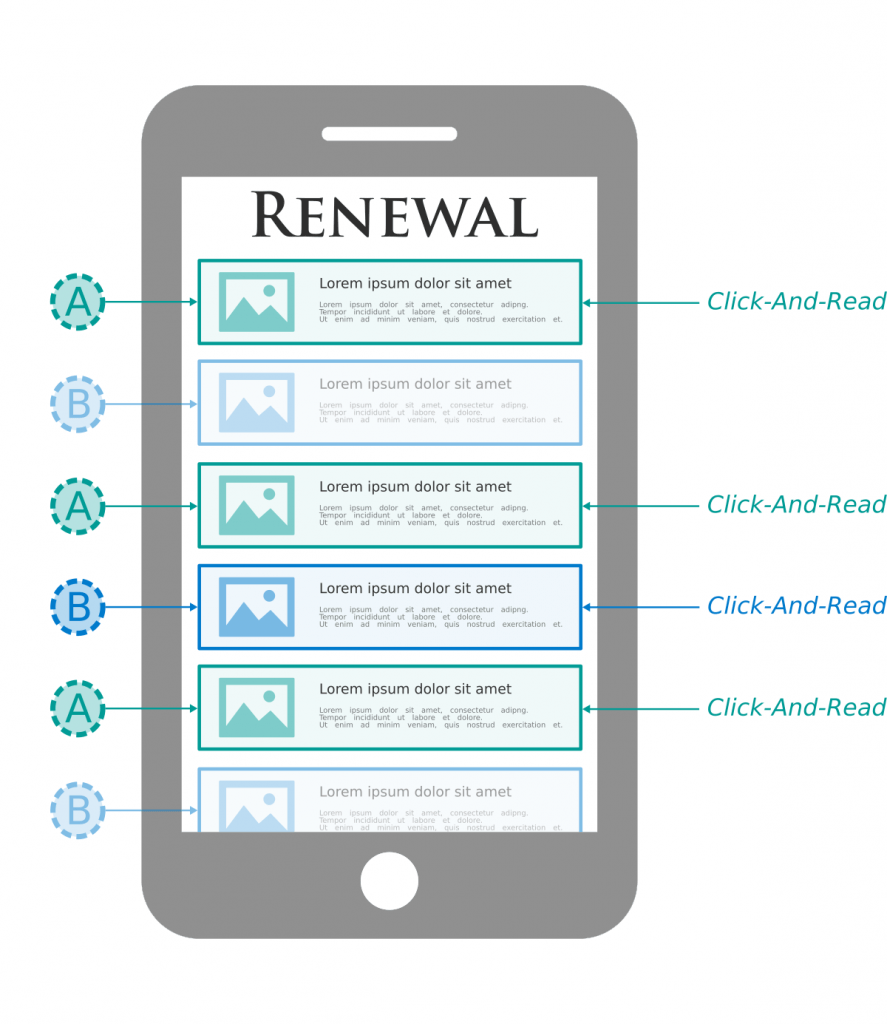
The figure below shows the modeling of the homepage of our mobile app. This page presents articles in a personalized way based on the user’s reading history. Various recommendations of articles are then displayed: some from system A and others from system B. This evaluation strategy is called A/B testing by interlace comparison. System A receives a larger number of Click-And-Read and will therefore be considered superior to the opposition.
The main difficulty is to be able to equally evaluate recommendation systems in real time, knowing that not all systems are used by all users. The “real-time” evaluation must be able to smooth the scores taking into account the differences between each user. A work of standardization for the users is necessary: those who read a lot versus those who read very little.
Another difficulty in the equitable evaluation of systems is the assignment of systems to users that corresponds to the comparisons observed. A system A may be compared with statistically less efficient systems than a system B. It will therefore be considered, perhaps wrongly, better than B whereas no A/B comparison has yet been observed. Our platform must be able to generate a real time ranking taking into account all these skews.
« This new KPI is called “Click-And-Read”. We introduce it into opposition in the form of A/B testing. »
Methods based on voting theory (e.g. Copeland method and random assignments to overcome this set of problems are being proposed. Funding in September 2019 from the LRI (Laboratoire de Recherche en Informatique) is allowing the development of the platform to continue.
We will test different real-time assessment strategies, including those proposed to date.
To be continued…