


Retour de pertinence – Projet R&D Octopeek
#HumanDataDans un précédent article, Julien Hay a introduit le projet Renewal. Ce projet a été présenté à la conférence NeurIPS en décembre 2018. Julien est Doctorant et Data Scientist, spécialisé en intelligence artificielle et en traitement du langage naturel (NLP). Cette plateforme est destinée aux équipes de recherche. Elle permet de tester et de confronter leurs algorithmes sur la tâche de recommandation d’articles d’actualités.
Dans ce second volet, Julien détaille le retour de pertinence qui permet d’effectuer le benchmarking temps réel des systèmes concurrents.

The Renewal Project – Le retour de pertinence
Le CTR (taux de clic) est un KPI très utilisé dans l’évaluation des systèmes de recommandation. Il permet de mesurer la performance d’un système par le nombre de clics qu’il génère normalisé par le nombre de fois que ses recommandations ont été affichées.
Le CTR présente quelques inconvénients
Le CTR permet d’indiquer à quel point un système est capable d’attirer par ses propositions d’articles et de générer des clics. En effet, à cette étape, l’utilisateur ne voit que le titre de l’article. Ceci avantage directement les “clickbaits” (pièges à clics). Il ne mesure pas la satisfaction réelle d’un utilisateur, pouvant être évaluée par le temps de lecture des articles ou une satisfaction exprimée explicitement. Il ne permet pas directement une confrontation de type A/B testing. (Cf. précédent billet)
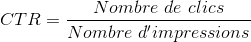
Le Click and Read, véritable KPI de satisfaction
Dans le cas de la recommandation d’articles d’actualités, la satisfaction d’un utilisateur est liée à son appréciation des lectures donc à ce que le système lui a recommandé. Le système doit recommander des articles suffisamment pertinents vis-à-vis des intérêts de l’utilisateur. Il doit également proposer du contenu nouveau qui permettra au lecteur de découvrir de nouveaux sujets d’intérêts.
Notre hypothèse est la suivante : plus l’utilisateur reste longtemps sur la page et parcourt entièrement une page d’article, plus il apprécie la recommandation d’article qui lui a été proposée. La satisfaction d’un utilisateur est calculée à partir du temps de lecture et de la longueur du scroll de la page.
Quand l’utilisateur a lu un article suffisamment longtemps selon un seuil défini à l’avance, nous considérerons que le lecteur est satisfait (feedback positif). Si l’utilisateur a cliqué puis quitté la page de l’article dans un court lapse de temps, il s’agit alors d’un feedback négatif. Ce retour de pertinence s’oppose au CTR puisque celui-ci considère tous les clics comme feedback positif.
Ce nouveau KPI s’appelle “Click-And-Read”. Nous l’introduisons dans une opposition de type A/B testing.
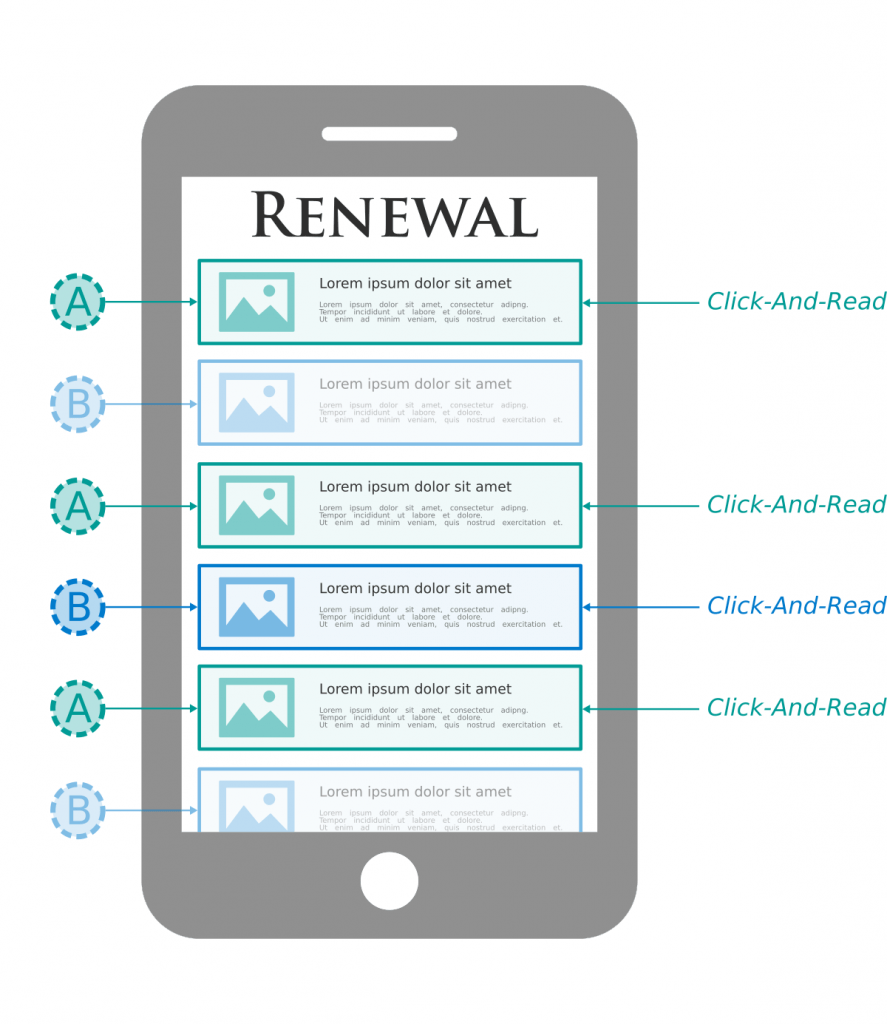
La figure ci-contre représente la modélisation de la page d’accueil de notre application mobile. Cette page présente des articles de façon personnalisée en fonction de l’historique de lecture de l’utilisateur. Différentes recommandations d’articles sont alors affichées : certaines du système A et d’autres du système B.
Cette stratégie d’évaluation est appelée A/B testing par comparaison entrelacée. Le système A reçoit un plus grand nombre de Click- And-Read et sera donc considéré supérieur dans l’opposition.
La principale difficulté est de pouvoir évaluer en temps réel les systèmes de recommandation de façon équitable sachant que tous les systèmes ne sont pas utilisés par tous les utilisateurs. L’évaluation “temps réel” doit être en mesure de lisser les scores en tenant compte des différences entre chaque utilisateur. Un travail de normalisation pour les utilisateurs est nécessaire : ceux qui lisent beaucoup versus ceux lisent très peu.
Une autre difficulté dans l’évaluation équitable des systèmes est l’assignement des systèmes aux utilisateurs qui correspond aux confrontations observées. Un système A peut être confronté à des systèmes statistiquement moins performants qu’un système B. Il sera donc considéré, peut-être à tort, meilleur que B alors qu’aucune confrontation A/B n’a encore été observée. Notre plateforme doit pouvoir générer un classement temps réel en tenant compte de tous ces biais.
Ce nouveau KPI s’appelle “Click-And-Read”. Nous l’introduisons dans une opposition de type A/B testing.Des méthodes basées sur la théorie du vote (e.g. méthode de Copeland) et des affectations aléatoires permettant de palier cet ensemble de problèmes sont en cours de proposition. Un financement du LRI (Laboratoire de Recherche en Informatique) permet de poursuivre en septembre 2019 le développement de la plateforme.
Nous testerons alors différentes stratégies d’évaluation temps réel dont celles proposées à ce jour.
A suivre…


